Removing Zinio DRM
Someone sent me an email a few weeks ago asking me if my Future plc downloader could also download Zinio magazines. I had no idea what Zinio is, so I visited their website to learn more about their platform. They call themselves “The World’s Largest Newsstand” and offer over 5500 magazines (including all of the Future plc magazines). Such a huge number of magazines instantly made them into a potential target for a DRM removal tool. I couldn’t find any existing tool that could convert Zinio magazines into PDF (or any other format), so I assumed they had some complicated DRM scheme. Initially, I was not interested in breaking it, but I kept the idea in the back of my mind anyway. One day I had a few hours to spare and decided to give it a try.
Initial investigation
If you search the internet for “Zinio PDF conversion”, one of the first results will be a page from the Zinio help center. The entry is called Zinio PDF Files and it says the following:
Zinio does not provide publication files in PDF format. Your digital edition can be downloaded and saved in a format optimized for a rich reading experience provided by the Zinio Reader software.
I’m all for a rich reading experience! Well, if they say the don’t provide magazines in PDF format, then it must be true. Or maybe not? It was easy to verify their claims. I created an account, purchased one magazine and downloaded their Windows desktop app from Microsoft Store. Using Everything, I quickly found the folder containing the issue I just downloaded:
To my eye, that sure looks an awful lot like a bunch of PDF files—Zinio app is yet another glorified PDF reader after all. I tried to open one of the files, but I got the result I expected: encrypted PDF files, we meet again!
Decompiling Zinio app
I usually start with reversing the network API, but this time I changed the process and started with decompiling the app first, because trying to decrypt the files is way more fun. Zinio app targets both Windows 8.1 and Windows 10, which means it’s not compiled using .NET Native and can be trivially decompiled. This time I used dnSpy, which is my new favorite tool for decompiling .NET applications (it’s lightning fast and has great search capabilities, among many other great features). I loaded the Zinio app assembly and searched for “password”. The search returned only a few results, and one of them was this function in the ZinioReaderWin8.Util.CryptoUtils class:
public static string GetPdfPassword(string cipher, string password, string deviceId, string uuid)
{
IBuffer iv = CryptographicBuffer.DecodeFromBase64String(cipher);
IBuffer data = CryptographicBuffer.DecodeFromBase64String(password);
string s = "8D}[" + deviceId.Substring(0, 4) + "i)|z" + uuid.Substring(0, 4);
byte[] bytes = Encoding.UTF8.GetBytes(s);
IBuffer keyMaterial = CryptographicBuffer.CreateFromByteArray(bytes);
SymmetricKeyAlgorithmProvider symmetricKeyAlgorithmProvider = SymmetricKeyAlgorithmProvider.OpenAlgorithm("AES_CBC");
CryptographicKey key = symmetricKeyAlgorithmProvider.CreateSymmetricKey(keyMaterial);
IBuffer buffer = CryptographicEngine.Decrypt(key, data, iv);
return CryptographicBuffer.ConvertBinaryToString(BinaryStringEncoding.Utf8, buffer).Substring(0, 32);
}
This looked like it would be a very quick game over for Zinio. This function tells us that the PDF password is encrypted with AES-CBC using the 128-bit key derived from parameters called deviceId and uuid (initialization vector is passed via cipher parameter). But where are all these parameters coming from? GetPdfPassword is called only from IssueDataHelper.DecryptPdfPassword, and DecryptPdfPassword is called only from ZinioReaderWin8.Services.IssueDataHelper.ParsePackingList. Here are the most important lines of the ParsePackingList function:
IEnumerable<XElement> source = xmlTree.Descendants("trackingCode");
if (source.Count<XElement>() != 0)
{
xElement = source.First<XElement>();
}
if (xElement != null)
{
string value2 = xElement.Attribute("init").Value;
string value3 = xElement.Value;
SettingManager instance = SettingManager.Instance;
issue2.PdfPassword = IssueDataHelper.DecryptPdfPassword(value2, value3, instance.DeviceId, instance.InstallationUUID);
}
This code loads the XML node called trackingCode from some larger XML document, and extracts the IV and the ciphertext from it. My assumption was that the XML was received over the network when the user logs in or asks for magazine’s metadata. But what about the remaining parameters, deviceId and uuid? It turns out they are static values initialized in ZinioReaderWin8.SettingManager.InitDefaultSettings function:
private async Task InitDefaultSettings()
{
this.InstallationUUID = "4f867a26-8cf9-4a5b-a15a-9eba77365031";
this.DeviceId = "4860DBAD-768D-40B5-8BD0-F60224B451D5";
}
That was all I needed from the decompiled application. I had an algorithm for deriving the PDF password, so all that was left was to reverse the API.
Reversing the API
This part of the process was straightforward. Zinio API is super simple, with only three interesting requests: authenticateUser, libraryService, and issueData. Each request and response are self-contained XML documents, without custom HTTP status codes and headers; that made my job even simpler. The API doesn’t even use cookies or authentication tokens: email and password are stored on the client and sent with each request (that means the authenticateUser request is completely redundant, but it still exists for some reason). The client calls the libraryService to download the list of all purchased issues, and then issueData is called for each of them in order to retrieve all the data necessary to download it. Here is how issueData request looks in practice:
<zinioServiceRequest>
<requestHeader>
<authorization>
<login>user@example.org</login>
<password>secret123</password>
</authorization>
<device>
<profileId>9069154355</profileId>
<deviceId>A6B50079-BE65-44D6-A961-8A184AA81077</deviceId>
<deviceName>iPhone</deviceName>
<installationUUID>84A8E36D-DF7F-4D7E-9824-F793AFB93207</installationUUID>
<platformDescription>iPhone7,2</platformDescription>
</device>
<application>
<applicationName>Zinio iReader</applicationName>
<versions>
<version key="application" value="20160314"/>
</versions>
</application>
</requestHeader>
<libraryIssueDataRequest>
<pubId>373124878</pubId>
<issueId>416397519</issueId>
</libraryIssueDataRequest>
</zinioServiceRequest>
There are a lot of parameters here, and all of them are required. Login and password don’t need an explanation. deviceId and installationUUID are needed because server has to generate an AES key from them. applicationName is required for the reason I’ll explain later, and the others are required for no apparent reason. The server responds to this request with the following response:
<singleIssue>
<pubName>Maxim</pubName>
<pubId>373124878</pubId>
<issueTitle>December 2016</issueTitle>
<issueId>416397519</issueId>
<hostName>imgs.zinio.com</hostName>
<issueAssetDir>/repository/373124878/416397519/PDF/</issueAssetDir>
<trackingCode init="ctc93wsBTvmpa3AjKjLo5g==">vx3LmecwiYvazAjVTJRwMSb+9zY4oPNAjDoUYXppG/ZiMPhipsCCnSAyNCPE1yRr</trackingCode>
<numberOfPages>100</numberOfPages>
</singleIssue>
Remember the XML document containing the encrypted PDF password? This is it. It also contains the hostName and issueAssetDir; when combined, they give us the folder where PDF pages are located. I was slightly surprised when I found out that the PDF files don’t require any authentication. That worried me a little, because if the password was same for all the magazines, my program would allow users to download every available magazine for free, which was not my goal. Fortunately, I discovered later that each magazine issue has unique and randomly generated 128-bit PDF password (at least I hope it’s randomly generated—it could also be an MD5 hash of something).
Now I had all the parameters needed to determine the PDF password, but the code that I wrote didn’t work as expected. Decrypted PDF password was not a human-readable string, which didn’t look right. Server was also generating different IV each time, but that should have affected only the ciphertext—password should have been the same each time. That was not the case when I ran my code: decrypted password was different every time. There are only three parameters used in AES-CBC decryption: the key, the initialization vector and the ciphertext. That meant my decryption key was wrong. I compared my implementation with the original C# code multiple times, but couldn’t find anything wrong in my code.
Finally, after dozens of unsuccessful attempts, an idea came to my mind: what if the key derivation is platform dependent? Maybe the problem was that I decompiled the .NET desktop version of the app, but reversed the API using the iOS app (I have Windows only in virtual machine, so I try to use it only when necessary)? After replacing “Zinio iReader” with the “ZinioWin8” in the applicationName parameter, everything was working: decryption resulted in a nice 32-byte hex-encoded string! Few more hours of coding and my application could download, decrypt and merge individual files into a single PDF.
Removing annotations
After opening the generated PDF file, I noticed an ugly blue square at the upper-left corner of each page:
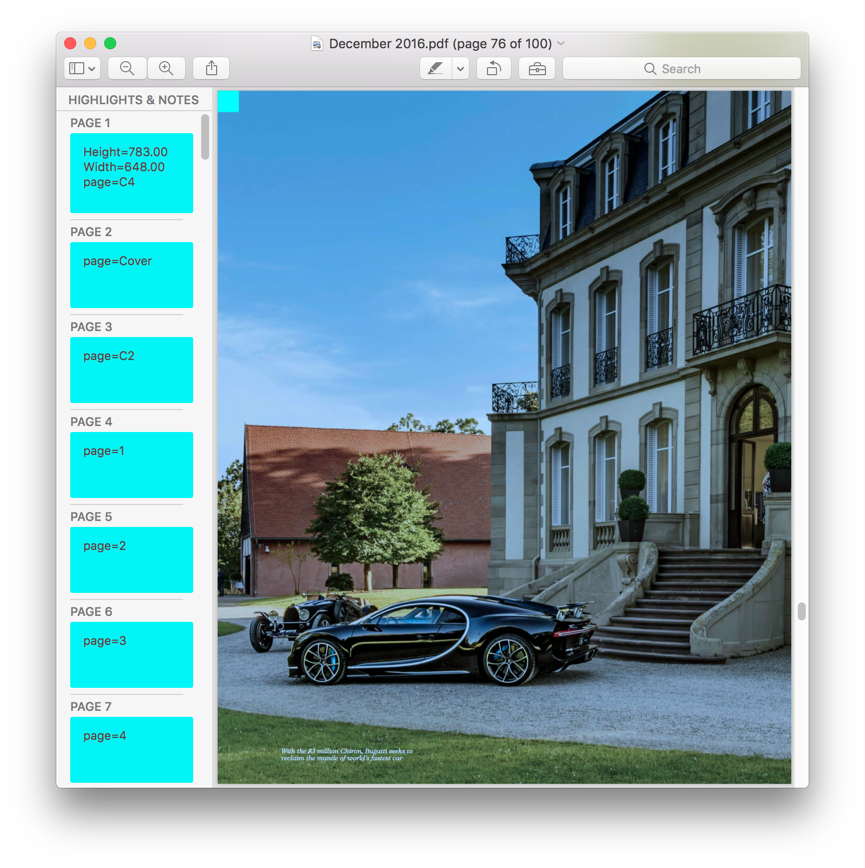
Each page apparently had an useless annotation containing the page number. You might remember that I had similar problem with annotations before), but this time they were much more obtrusive; I had to find a way to remove them.
As I mentioned previously, I’m using UniDoc for decrypting and merging individual PDF pages. I was hoping that the library could also remove annotations. Examples section on their website didn’t have what I needed. Unfortunately, their API documentation is next to useless: most of the functions didn’t have any documentation at all, which is a shame, because the library itself is really useful. I started looking for any type or function that looked like it could have anything to do with annotations.
I discovered an interesting type called PdfObjectDictionary. PDF file itself is a collection of objects, so there might be a way to find annotations by name and set their values to null or something like that? PdfPage type has GetPageDict method that returns PdfObjectDictionary, so I thought I was on to something. But my editor didn’t find GetPageDict method. What was going on? Here is the code for reading the decrypted PDF page and adding it to a final PDF:
page, err := pdfReader.GetPage(pageNum)
if err != nil {
return err
}
err = pdfWriter.AddPage(page)
if err != nil {
return err
}
Documentation for GetPage says it returns PdfObject, not PdfPage, but there is another function called GetPageAsPdfPage that actually returns PdfPage. Well, that is a very confusing API, but let’s try it. Now AddPage call couldn’t compile, because it only accepts a PdfObject and not a PdfPage. How to get the PdfObject out of the PdfPage? Obviously, by trying each available method until the program compiles! Calling GetPageAsIndirectObject did the job, whatever indirect object was. I started looking through autocompletion suggestions and found a field called Annots. Let’s set it to null! My final code looked like this:
page, err := r.GetPageAsPdfPage(i + 1)
if err != nil {
return nil, err
}
page.Annots = nil
if err = w.AddPage(page.GetPageAsIndirectObject()); err != nil {
return nil, err
}
Success! Annotations were gone and my application was complete. You can download it here.