Cosmos DB capacity pitfall: When more is less
You can use Cosmos DB to burn money, but you can also use it as a database. Cosmos DB is horizontally scalable, which means that you can always increase the capacity of the system on the fly, as long as you partition your data well enough. Here is what Cosmos DB documentation says about choosing a good partition key:
If you choose a partition key that evenly distributes throughput consumption across logical partitions, you will ensure that throughput consumption across physical partitions is balanced.
This is solid advice, but it’s not sufficient to ensure the optimal usage of provisioned capacity (even if you have perfectly balanced logical partitions). In this post, I’ll show you one counterintuitive scenario where even after making all the right design choices, provisioning more capacity can lead to less throughput consumption, and even throttling.
Experiment
Let’s say that you have designed the following system:
- You have 1,000,000 users.
- Users are stored in database
dband containerusers. - Users are partitioned by unique
userIdproperty. - Traffic is uniformly distributed between all users.
On the surface, this seems like a good design:
- You have wide range of possible partition key values.
- Each user belongs to its own logical partition.
- Throughput consumption is evenly distributed across logical partitions.
All these properties together should guarantee that throughput is equally distributed across physical partitions. Let’s see if that’s true.
You can use Cosmos DB .NET benchmark tool to simulate this system (the tool is a hidden gem of Cosmos DB ecosystem, and I can’t recommend it enough). But you can’t use it out of the box. I had to make two changes in the code to make it work in this specific scenario:
- Randomly generate the partition key by choosing a number between 0 and 1,000,000
- Apply rate limiting to outgoing Cosmos DB requests to keep the load at the same level
Let’s begin the simulation by provisioning 18,000 RU/s on the users
container. After running the tool for a few times with the different
load, you figure out that 1,300 requests per second will consume all
available throughput:
dotnet run CosmosBenchmark.csproj \
-e $ACCOUNT_ENDPOINT \
-k $ACCOUNT_KEY \
--database db \
--container users \
-w InsertV2BenchmarkOperation \
-n 1000000 \
--partitionkeypath /userId \
--pl 100 \
--rps 1300
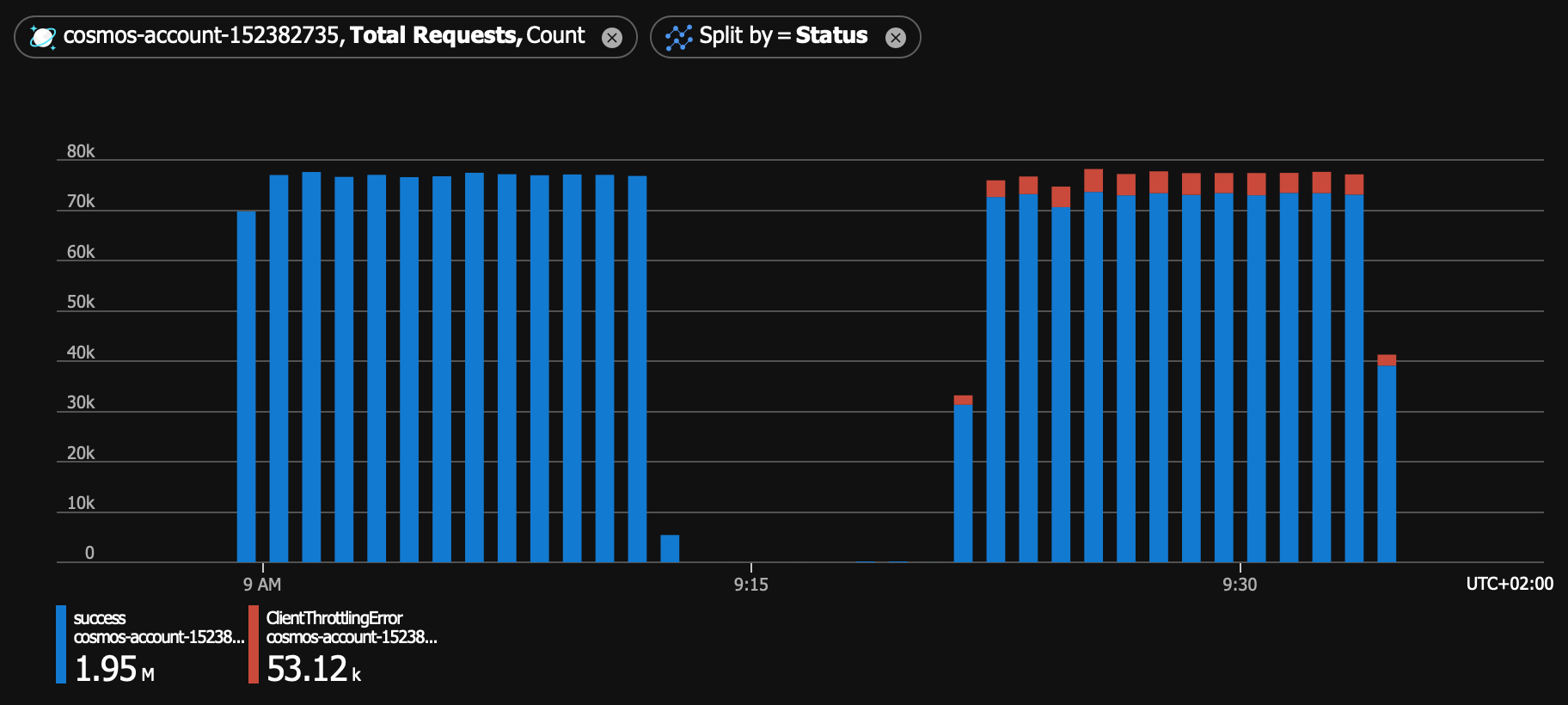
Now let’s imagine you are expecting that users will start using your system more, so you preventively increase container’s throughput to 21,000 RU/s. You think that this change should not make any visible difference under the same load (higher throughput should only ensure that the system can handle more traffic in the future). But you run the tool again (with the same parameters), and you see some very confusing results:
| 18,000 RU/s | 21,000 RU/s | |
|---|---|---|
| Total | 1,000,000 | 1,000,000 |
| Success | 1,000,000 | 946,881 |
| Fail | 0 | 53,119 |
| RPs | 1,284 | 1,286 |
| RUps | 17,854 | 16,928 |
In both cases, you applied the same load (slightly below 1,300 requests per second). But after you provisioned more RUs, you consumed less of them. Not only that, but more than 5% of all requests were unexpectedly throttled. You can clearly see the difference between two runs in this Azure Monitor chart:
What is going on here?
Cosmos DB partitioning documentation says that:
Unlike logical partitions, physical partitions are an internal implementation of the system and they are entirely managed by Azure Cosmos DB.
Unfortunately, even though Cosmos DB tries to hide its implementation details, sometimes you will need to know what is going on behind the scene. I’ll use the results of the previous experiment to show you why.
Container with 18,000 RU/s will most likely have two physical partitions (it can actually have more, but I’m ignoring these cases because they are not relevant for this discussion). Each of the partitions will handle roughly one half of the traffic (500,000 users and 9,000 RU/s):
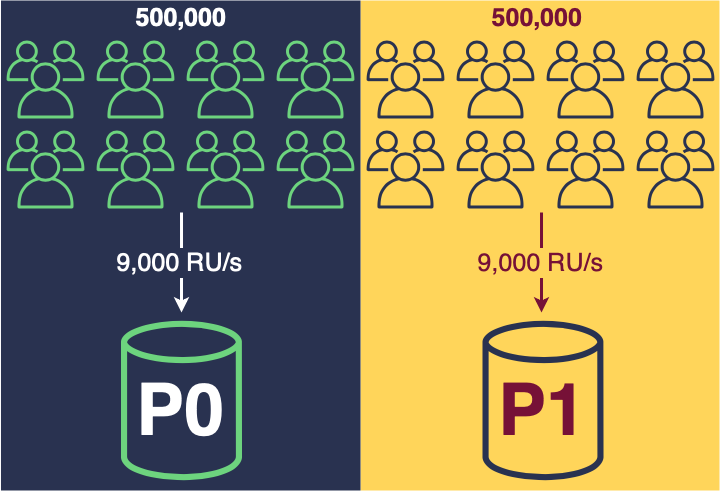
What happens when you provision 21,000 RU/s? Two physical partitions will no longer be enough to satisfy the increased throughput, since each physical partition is limited to serving at most 10,000 RU/s. Cosmos DB will create a new physical partition, and it will do that by splitting one of the existing partitions in two. The traffic between physical partitions will now be distributed like this:

Cosmos DB will not redistribute logical keys across all partitions, so one of the original partitions will remain as twice as big as two new ones (this applies to both throughput and storage).
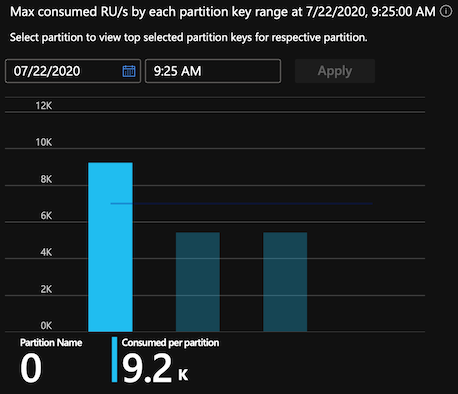
Even though nothing looks wrong in this picture (at least on the surface), now you actually have a capacity problem. Because container throughput is divided equally among partitions, each partition can now serve only up to 7,000 RU/s. But the first partition is still getting the same traffic (9,000 RU/s), which of course leads to throttling (this seems obvious now). Again, you can see this clearly in the throughput metrics section in the Azure portal (try to see the barely visible dark blue line at 7K, which shows the per-partition usage limit):
What can you do about this?
When you see throttling, your immediate reaction might be to provision more RUs. That will of course help, but it will also lead to spending much more money then you really need to. A better way to handle the problem of imbalanced physical partitions is actually pretty simple: when current number of physical partitions is not enough to handle the new throughput, always split all physical partitions (this will only help you when your logical keys are already evenly distributed, but not when you have a hot logical partition).
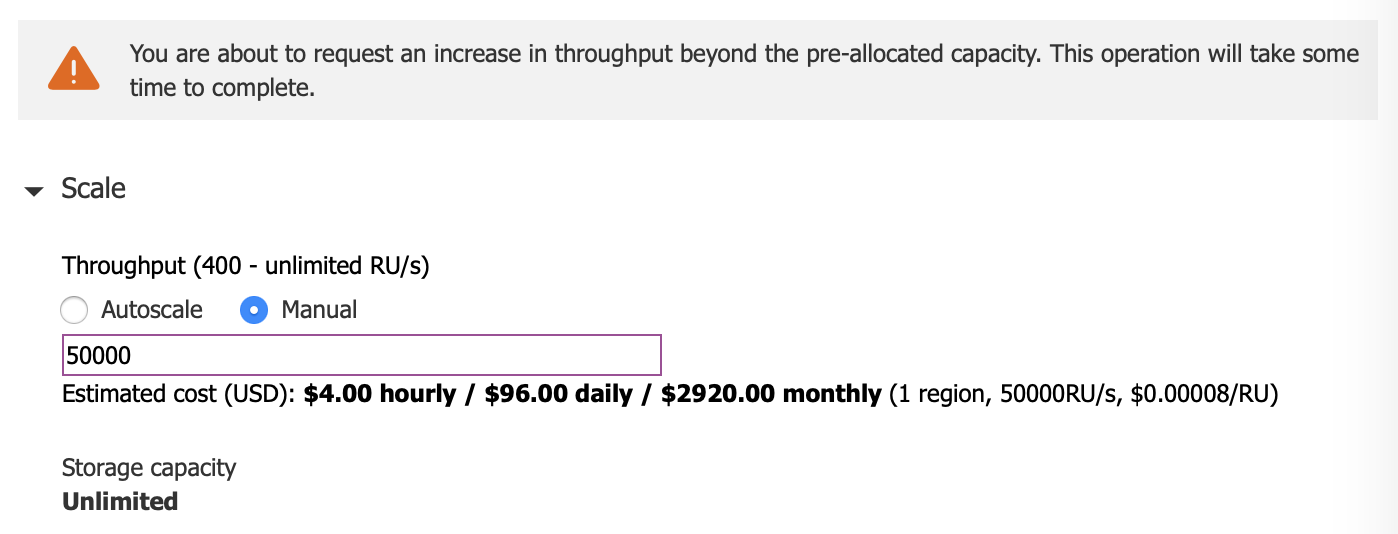
First, you have to know when increasing the throughput will create new physical partitions. Azure portal is nice enough to give you this warning when the partition split is about to happen:
Second, you have to figure out the current number of partitions in the container. You can do that by using REST API, Azure CLI, C# SDK, or any other Azure Cosmos DB client that supports retrieving all partition key ranges for a given container.
The third and the final step is to provision enough RUs so that all physical partitions will be split (after this operation completes, you can immediately lower the throughput to the value you actually want to use). You can use the following formula to calculate the needed throughput:
2 * number of partitions * 10,000
For example, if you have a container with 300,000 RU/s in 35 physical partitions, and you want to increase the throughput to 380,000 RU/s, you will have to:
- Provision 700,000 RU/s
- Wait until the operation finishes
- Decrease the throughput to 380,000 RU/s
That’s all! If this helps to you reduce your Cosmos DB monthly bill, feel free to send me thank you notes in the form of US dollars!